Python
grip: render Markdown as PDF
.. and other things, where you assumed it should be quite easy. ..
Wrote a short guide how to verify some information in Markdown. Local rendering works (most of the time via PyCharm or online at Github).
Now: how export it as PDF, because I realized that the receiver might not be able to display it properly.
* printing from PyCharm: failed
* VisualStudio-Plugin: no VS, no plugin
* any of the *nix-ways: not possible at that moment
* using a web-renderer: not allowed, because confidental data
UFF!
Python to the rescue!
|
1 2 |
pip install grip grip file.md |
Grip prepares a local flask server, where you receive a localhost:<randomport> url and just open it with the browser of your choice and then print as PDF.
Project Euler – mathematical riddles which require some programming skills
Took me a while to write about this, but I really love Project Euler. The page is a collection of math challenges, which require some programming (I saw just one which could have been computed by a closed formula without any help). The first ten are quite easy to solve and are more commonly known math problems. Prime numbers and combinatorics play a strong role. But then the difficulty rises quite quickly. Usually it takes me one to two hours to write a Python solution for one. If I would – like I should – write unit-tests for each single method and not for a few selected one, then I guess 50% more.
It’s great: each problem is a closed, separate problem, which requires some algorithmic thinking and – of course – some proper implementation. If you chose the wrong path time or space complexity will kill your ambitions quite quickly. But proper solutions are computed most of the time in less than a minute.
Most of the time I rely on basic python structures and common libraries. But I’ve also given NumPy, itertools, etc. a try. Speeds up the process quite a bit.
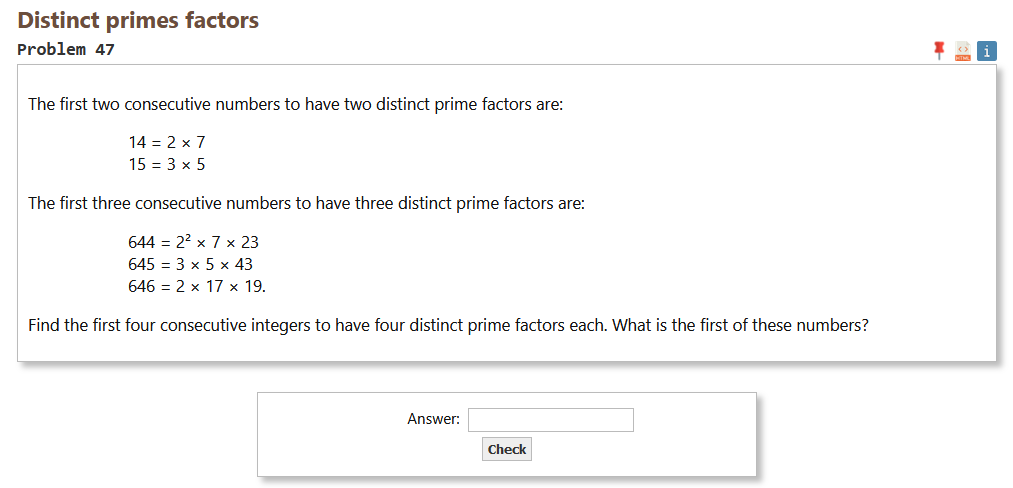 My next goal is to fix problem 47, because then I’ve handed in solutions for all of the first fifty problems.
My next goal is to fix problem 47, because then I’ve handed in solutions for all of the first fifty problems.
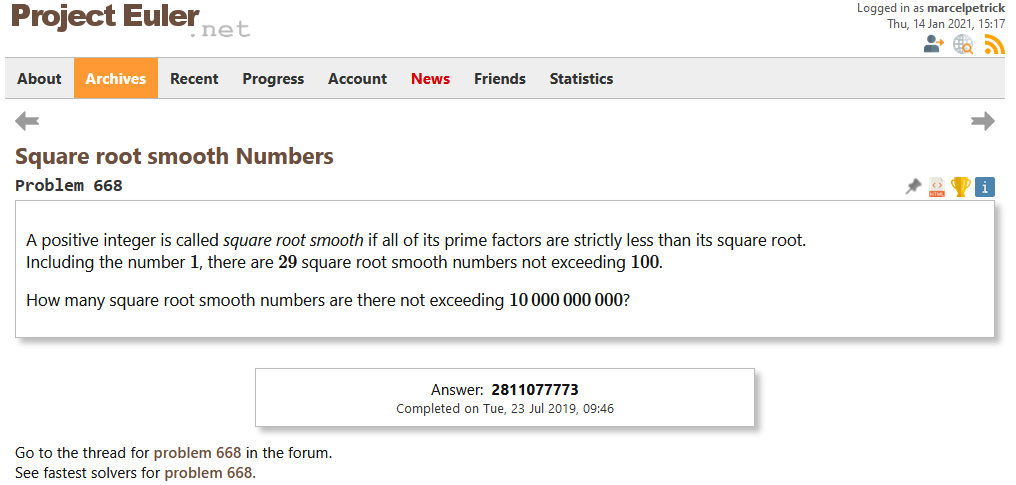
 The highest challenge (with also the highest difficulty level (for me) so far) was problem 668. Due to a really big (80 GiByte!) boolean array the computer had a hard time swapping memory. So it took almost 36 hours to finish. By the way: less than 900 people worldwide have solved this issue #tinyflakeofpride
The highest challenge (with also the highest difficulty level (for me) so far) was problem 668. Due to a really big (80 GiByte!) boolean array the computer had a hard time swapping memory. So it took almost 36 hours to finish. By the way: less than 900 people worldwide have solved this issue #tinyflakeofpride
 Of course, several geniuses have dedicated pages to optimal solution strategies. Which is a nice idea. But I avoid them. Most of the times stepping back, thinking without a display about the problem and if the chosen approach was a good one, is more helpful. A solution by cheating is nothing which renders any reward.
Of course, several geniuses have dedicated pages to optimal solution strategies. Which is a nice idea. But I avoid them. Most of the times stepping back, thinking without a display about the problem and if the chosen approach was a good one, is more helpful. A solution by cheating is nothing which renders any reward.
micro:bit v2 arrived :)
Today (finally) my micro:bit v2 arrived. Had to unwrap it immediately after dinner and play around with the speech synthesis👌🏻 Some lines of microPython and the things got heated.
If you’re not creating anything nowadays, then it’s your own fault 🐒


simple webscraper for last.fm with BeautifulSoup
tl;dr:
Simple webscraper with Python and BeautifulSoup for one user’s favorite tracks (‘loved songs’) at last.fm.
Repository: github
full text:
Looks like last.fm is shutting down its services (one feature at at time, lol). They started this process more or less ten years ago.
I’ve realized that I would miss my curated list of favorite tracks and I am also very bad at remembering, so … let’s automate the process of grabbing that information from their public page. I know, they offer a REST API, but I wanted to use once BS4.
Since I had somehow two free hours fourteen days ago, I went full-speed to some tutorials, played with the get-requests and how to parse. And then spent the last minutes parsing the received “artist+track”-string into something usable. Alltogether four hours were spent and I am amazed by the result. Of course, by leveraging three quite powerful libraries (beautifulsoup4, requests, lxml) and skipping TDD (;) I’ve reached the goal quite fast. And since the script works (my 1500 loved songs are scraped in less than 60 seconds), I will also not spend additional effort to make it “pretty”.
“[Full Day Workshop] Kubeflow + BERT + GPU + TensorFlow + Keras + SageMaker”
I’ve just spent the last eight hours attending a workshop about #SageMaker, #AutoPilot, #BERT, #Athena, #TensorFlow, #Spark, [..] and I am feeling a bit light-headed.
Of course, the talk and guidance given by @AntjeBarth and @ChrisFregly was really well prepared, but if you’re just a ML-beginner (like me) and if then over 9000 of new technologies drop, you have to work hard to follow the fast paced event.
Of course, I started my ML-journey in the summer of 2019, but it was more focussed on image-processing, not #NLP. I worked before with #Python, #Jupyter notebooks, TensorFlow and #Keras, but that whole SageMaker-thing was new to me.
And I see the potential: instead of running the stuff locally, you prepare, prototype and run your ML-app inside Amazon’s infrastructure. And that AutoPilot, which helps to quickstart the prototyping by trying several preprocessing-steps and models for you on your data, looks promising. Will definitely give it a second look.
Notes can be found at: https://github.com/marcelpetrick/KubeFlow_BERT_GPU_TensorFlow_Keras_SageMaker_Workshop (need lots of polishing, as always)
Crazy times we live in! And I am thankful for this block of time on a weekend 🙏
PyQt: GroundSpace
Over the past weeks I’ve worked on a small project to combine the best of the Qt and Python domains. It was time to put both together. I knew about the PyQt- (Riverbank) and PySide- (Qt) bindings for years, but never really dipped my feet into those water. It was time to fix this.
GroundSpace (wordplay) is a small tool to fill your hard-disk (SSD ..) with arbitrary content. To test the speed of writing and to create big chonks of data.
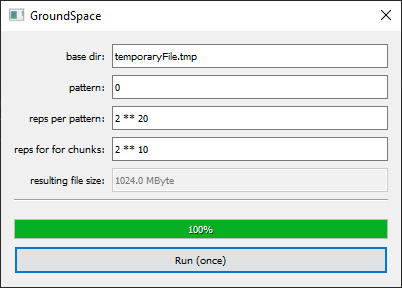
What was learnt?
* creating an ui-file with QtDesigner (jk, I knew this) and how to pre-compile it for PyQt-usage
* loading that uic-file and creating connections
* progress-callback
* how evil the ‘eval()’ function in Python is
Next stop: I want a proper web-scraper in Python.
GitShortlogToPieChart (Python: Git ➔ matplotlib)
Time to turn the spotlight on for a tiny project I’ve finished five weeks ago. The plan was to create a script, which would retrieve the of commits for the current repository for each committer (without those distorting merge-commits) and create a piechart-plot out of it and save as raster-graphics.
Implementation was more or less straight-forward, but again – I learned a lot. Talking is one thing, creating some usable proof-of-concept is the other. And words are cheap. No matter how triftling the task may seem, action speaks louder than “ah, shouldn’t be a problem”.
Actually I had done this before the Python-graphics-workshop, because even before I thought the matplotlib is quite a mighty tool which will come in handy.
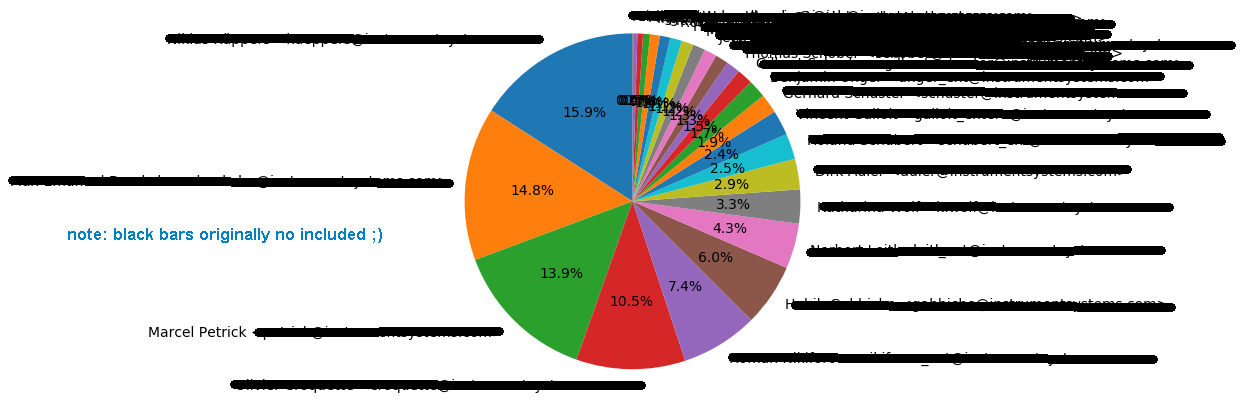
Project can be found here: GitShortlogToPieChart
Call like this:
|
1 2 |
$ python /coding/pythonCollection/GitShortlogToPieChart/GitShortlogToPieChart.py (lol) |
workshop: Graphics with Python
Initial plan was to visit a course at the VHS (MVHS: Münchner Volkshochschule) about ‘NLP with Python & DeepLearning’ (natural language processing). But the tutor quit, so I checked what else I could learn! Notes and examples are archived here: graphicsWithPython
The course took place on two evenings. Lecturing person was Dr. Günter Spanner. We coasted through examples with matplotlib, tkinter and pygames.
Of course, tkinter is available out of the box with newer Python-distributions. But the resulting GUI is butt-ugly (I feel like using those UNIX-workstations in the first semester of computer science..) and you have not much influence on the layout. Since I am working for some while now in the background with PyQt (will be covered in one of the upcoming posts), I can say: good that I had a hands-on, but I will NOT use that.
matplotlib: high value in quick generation of plots of all kinds (bars, line-charts, pie-charts, ..). I’ve used it before and I guess this is the main earning from this learning-opportunity.
pygames: loading some graphics, adding a game-loop, reacting to user-input, all fine. But would require some additional effort for understanding. Maybe in the future.
Conclusion:
Of course, a two-day workshop can’t provide you with credible knowledge and expertise for three frameworks. But having a teacher can ease the starting-pain and allows quick feedback in case something does not work. For me it was also a good opportunity to have some exchange with people and some learning-atmosphere. Also: since tkinter is so butt-ugly, I got further momentum continuing my PyQt-project.
MicroPython (uPython) – the future is here
My activity with the ESP8266/ESP32 boards had somehow fallen asleep after I set up one of the ESP8266 as Wifi-repeater. It worked, but creating own devices was too cumbersome. Firing up the ArduinoStudio took ages, building and downloading the firmware in C++ was error-prone, took ages (seriously, this is a tiny program, what the hell happens in the background?).
But I knew there exists a path, which could save some time: µPython (micropython). It runs a firmware, you just deploy your “code”. In my case now a tiny hello-world-like program.
I used this and that tutorial and the uPyCraft-IDE. Got it working with an ESP8266 in minutes.
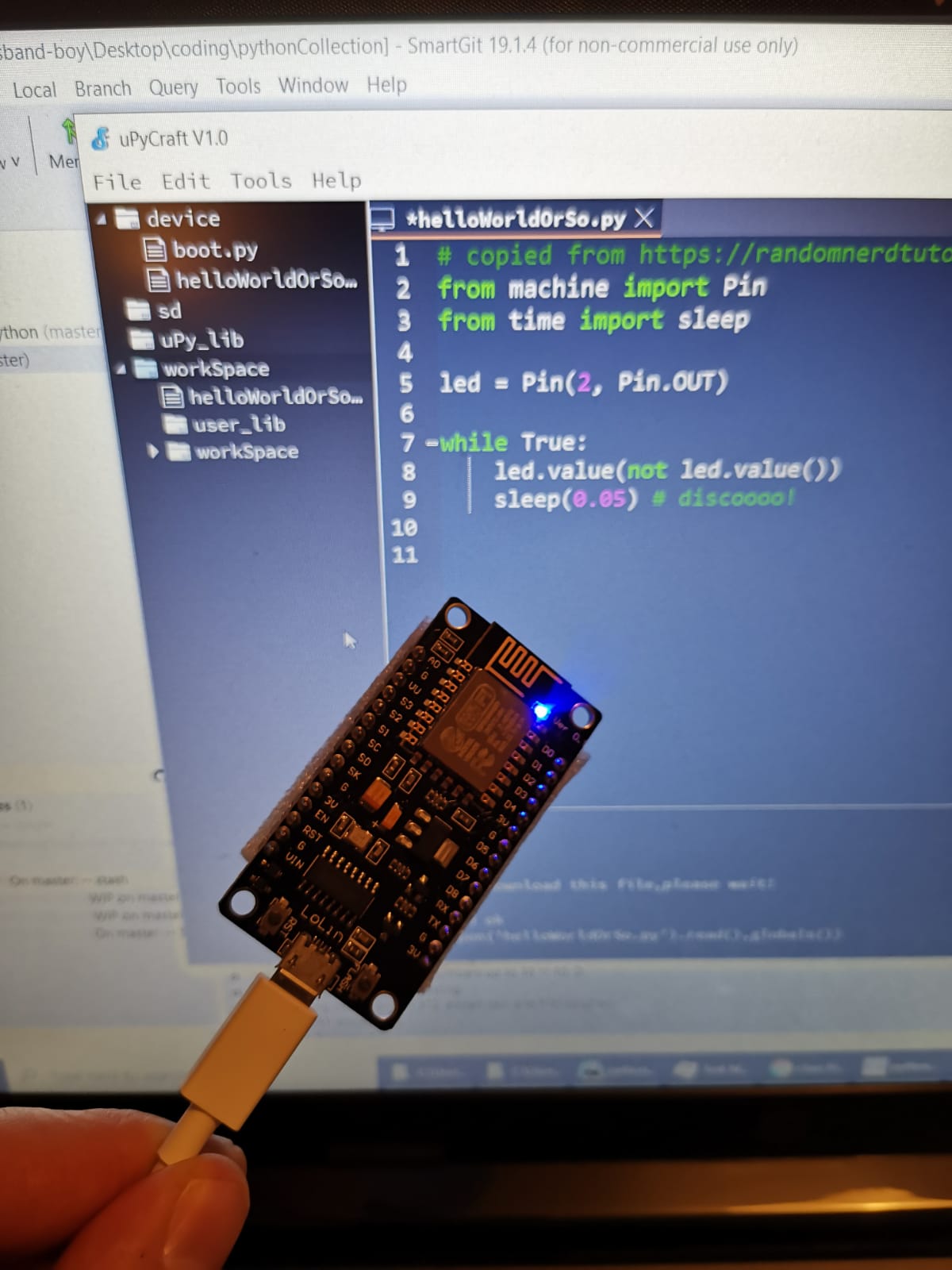
Seriously: goodbye crappy, non-structured and slow-to-build C/C++ for my microcontrollers. The future is here o/
By the way: the motivation also comes from my current daily practice of Python (of course, I still contribute to C++/Qt-based projects), but my current flame is Python (for Project Euler and daily coding challenges).
python: maximum size of certain containers
Getting the 64 bit version is quite important. Still don’t get it why for Win the 32 bit one was preferred ..
|
1 2 |
import sys print(sys.maxsize) |
32 bit: 2147483647 (elements)
64 bit: 9223372036854775807 (elements)
20190711 edit: even if the container could keep that much elements – remember that [Boolean] is 24 Byte (intead of one Bit) in vanilla Python. Means: if you run out of real memory, then MemoryError :/